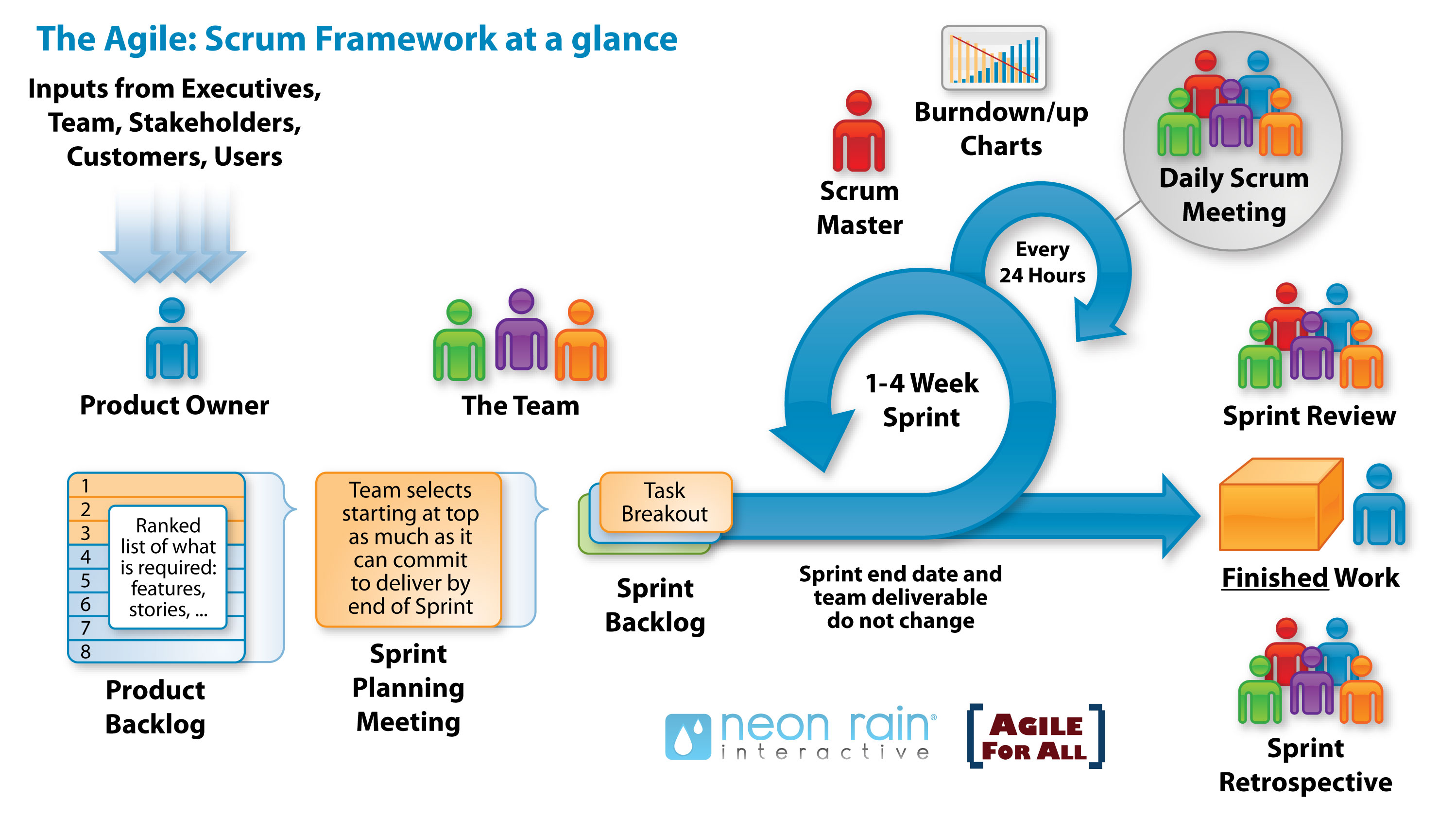
01 | 基础架构:一条SQL查询语句是如何执行的?
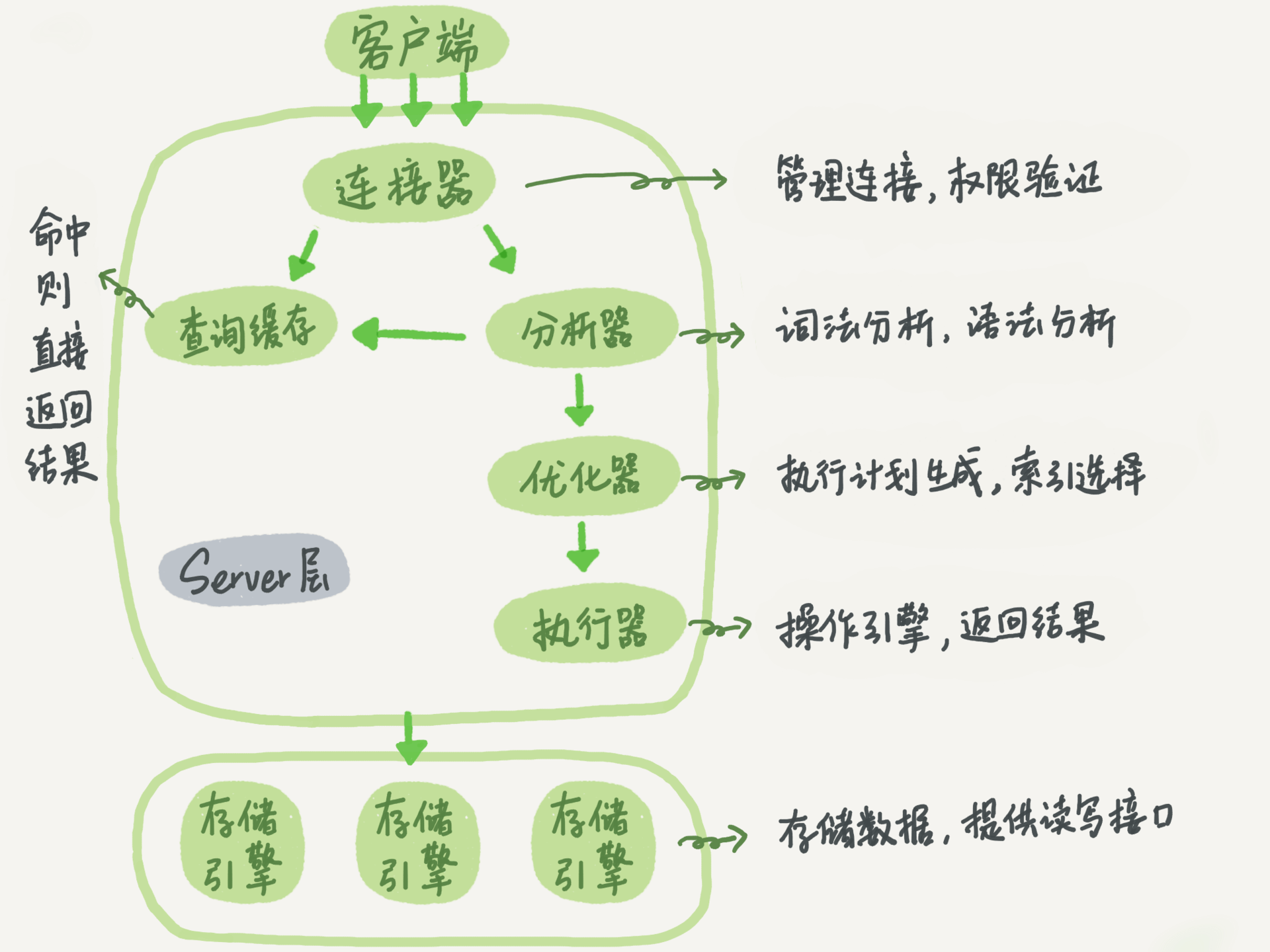
Notes: 查询缓存已经在MySQL8.0删除了,之前版本不推荐用,更新任意表数据就会全部清空
02 | 日志系统:一条SQL更新语句是如何执行的?
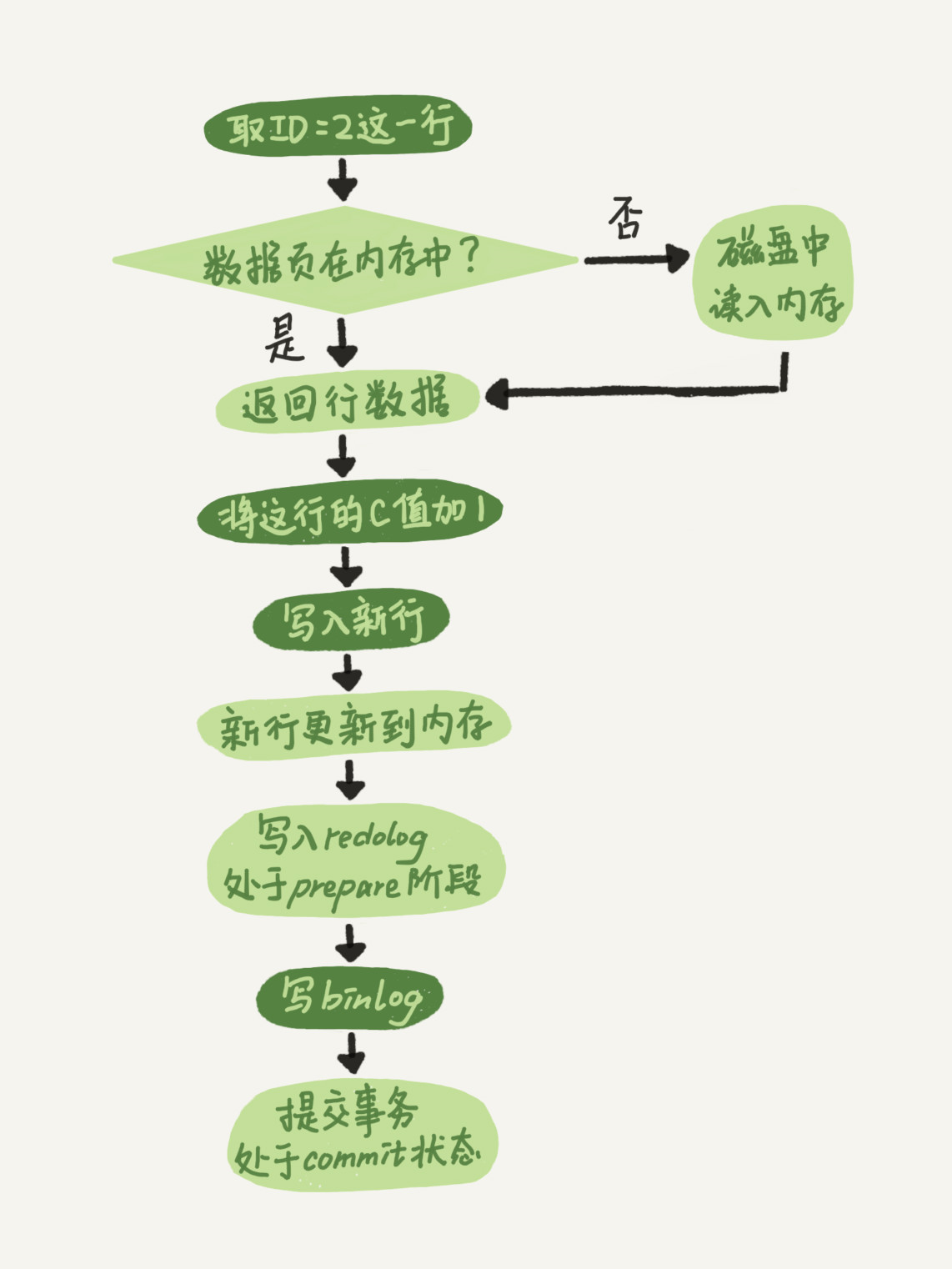
上面的查询流程也是会走一次的,但是涉及到两个重要的日志模块:redo log和binglog。
-
redo log:
- 存储引擎层,是InnoDB特有的。
- 记录的是物理上存储内容,更新时,先保存到redo log然后一定时间后再同步到磁盘的数据上。
- 循环写的,固定空间的会用完。
-
binglog:
- Server层,所有引擎都是有的。
- 记录的是逻辑日志,记操作了什么,更新了什么字段
- 一直追加的,当达到设定的文件大小时,就会产生新的日志文件
- 有三种模式:
- statement 格式的话是记sql语句,默认使用
- row格式会记录行的内容,记两条,更新前和更新后都有
- mixed为上两种的混用,先statement保存,无法保存时保存为row
-
已下更新SQL语句的执行流程 --二阶段提交(浅色在InnoDB中, 深色在执行器中)
update T set c=c+1 where ID=2;
03 | 事务隔离:为什么你改了我还看不见?
隔离级别
- 读未提交(read uncommitted)是指,一个事务还没提交时,它做的变更就能被别的事务看到。
- 读提交(read committed)是指,一个事务提交之后,它做的变更才会被其他事务看到。
- 可重复读(repeatable read)是指,一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
- 串行化(serializable ),顾名思义是对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
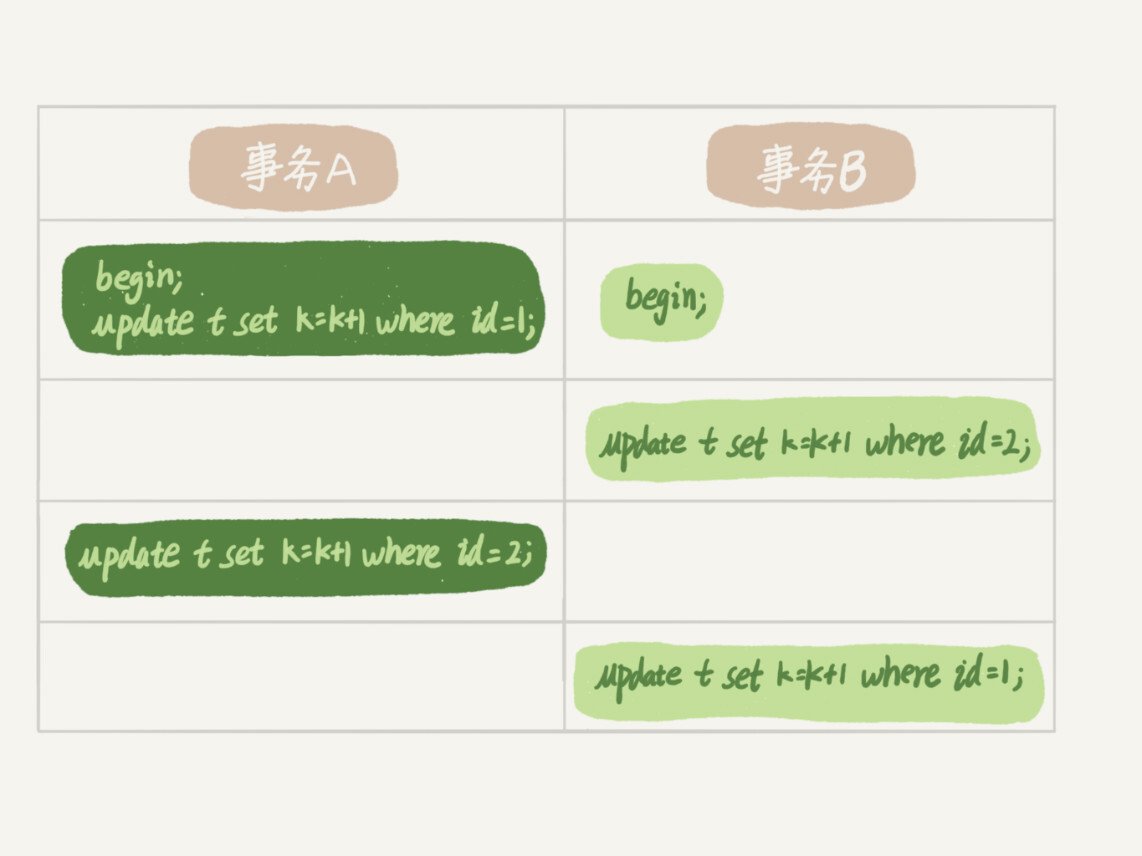
思考下图情况,在不同事务隔离级别时的结果:

- 若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2。
- 若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。
- 若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
- 若隔离级别是“串行化”,则在事务 B 执行“将 1 改成 2”的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。
查看mysql事务级别,Oralce默认为 read-commit。
show variables like 'transaction_isolation';
04 | 深入浅出索引(上)
索引的常见模型
- 哈希表: 是一种以键 - 值(key-value)存储数据的结构,哈希表这种结构适用于只有等值查询的场景。
- 有序数组: 在等值查询和范围查询场景中的性能就都非常优秀,有序数组索引只适用于静态存储引擎。
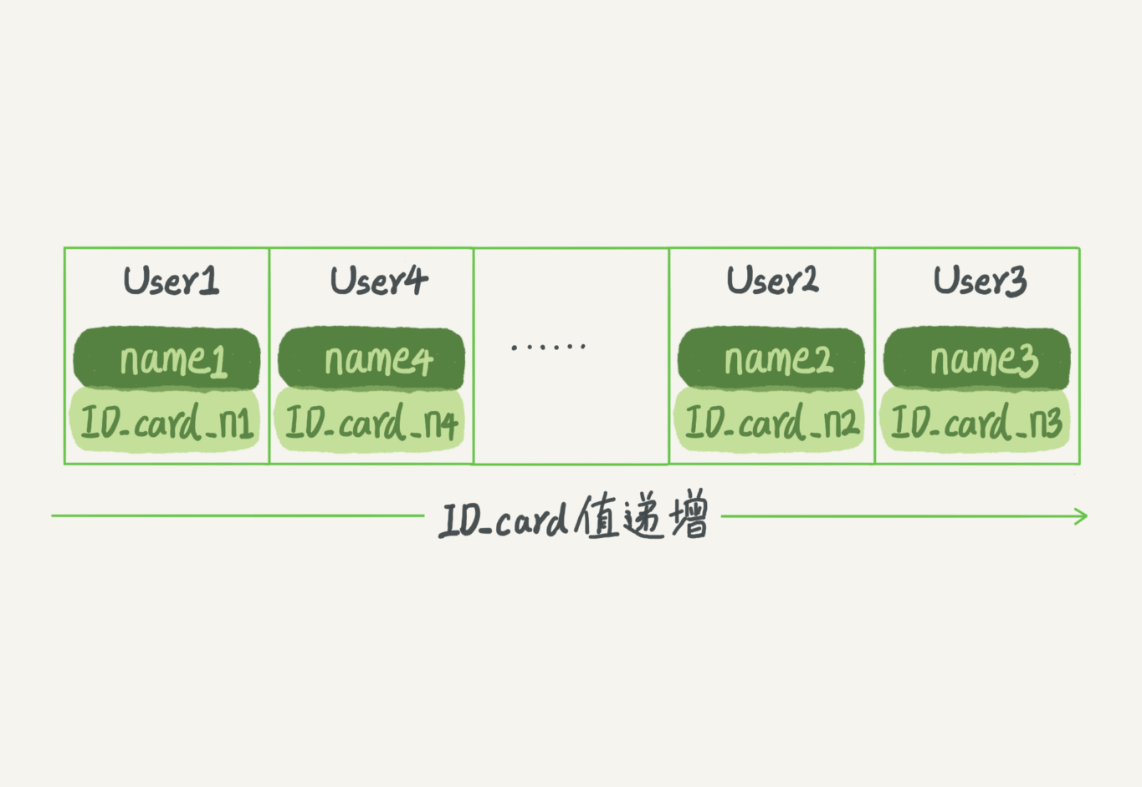
- 二叉搜索树: 可以减少查询,适合数据库这样的磁盘读取。
InnoDB 的索引模型
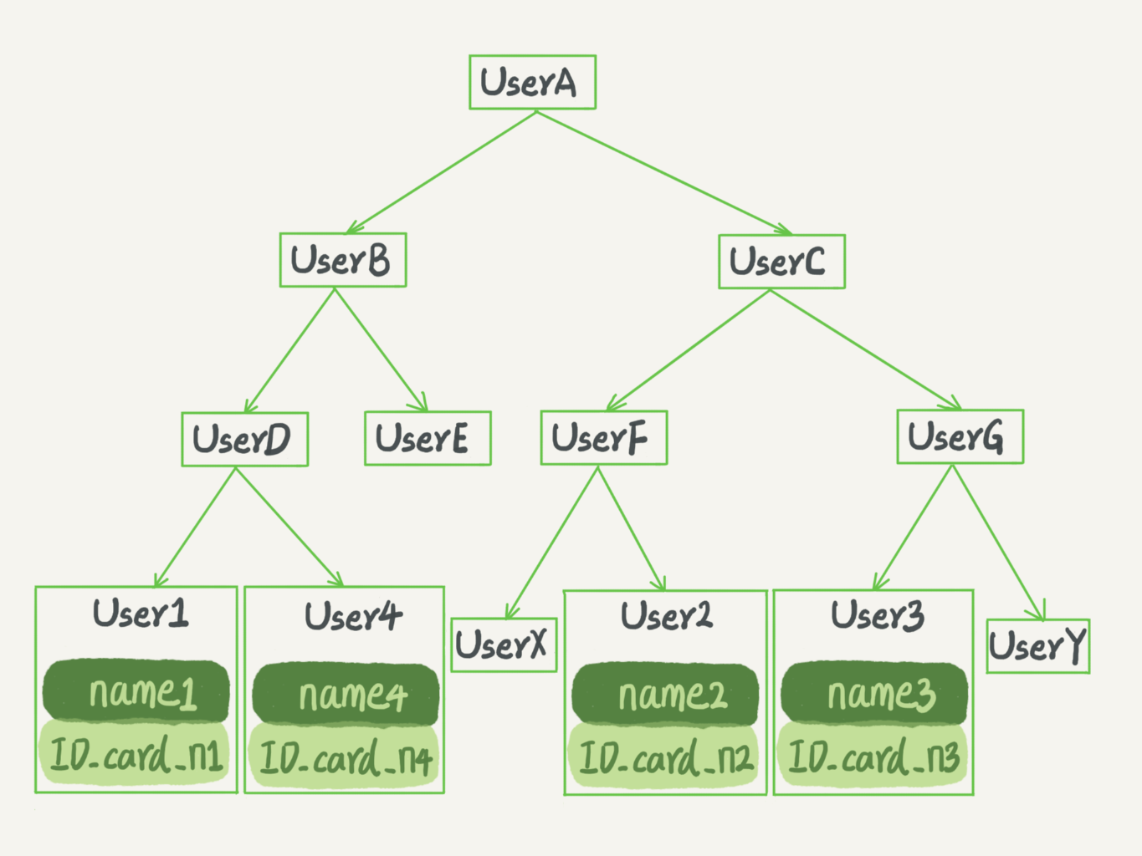
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。InnoDB是使用了B+树索引模型的。
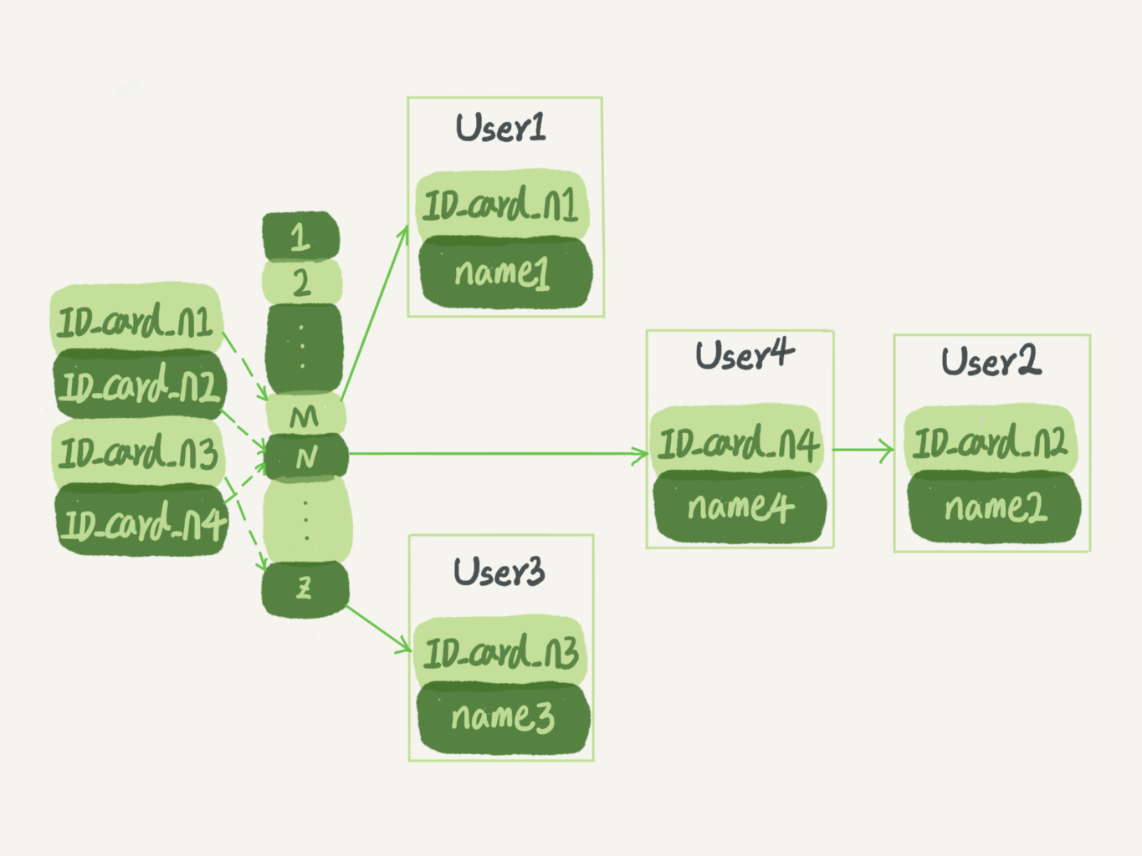
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。所以还需要基于主键的索引二次查询一下,这样叫回表。
- 由于每个非主键索引的叶子节点上都是主键的值,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
05 | 深入浅出索引(下)
覆盖索引
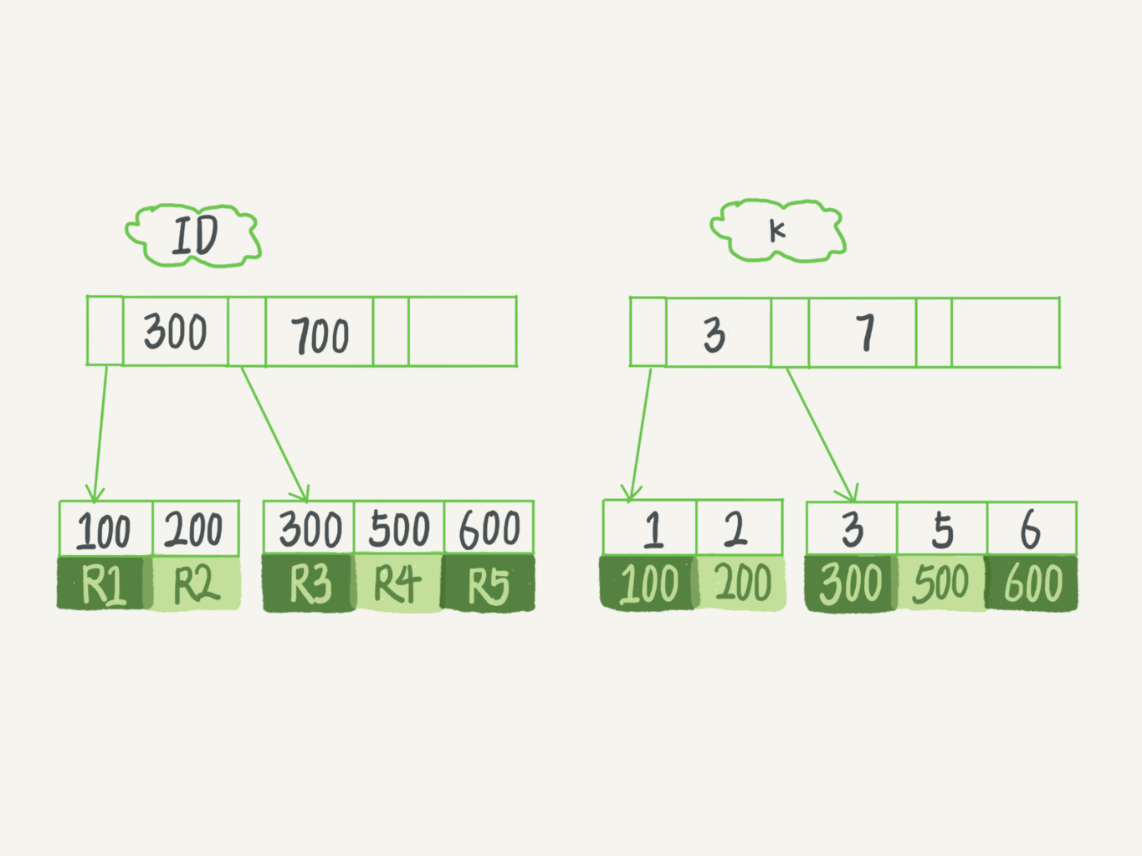
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。
也就是说查询语句指定是索引的字段,这样会显著的提升查询的速度,这是个通用的性能优化手段。
最左前缀原则
联合索引的时候,是利用最左边的前缀来定位记录。如(name, age),name就是执行索引的字段。
如果既有联合查询,又有基于 a、b 各自的查询呢?查询条件里面只有 b 的语句,是无法使用 (a,b) 这个联合索引的,这时候你不得不维护另外一个索引,也就是说你需要同时维护 (a,b)、(b) 这两个索引。
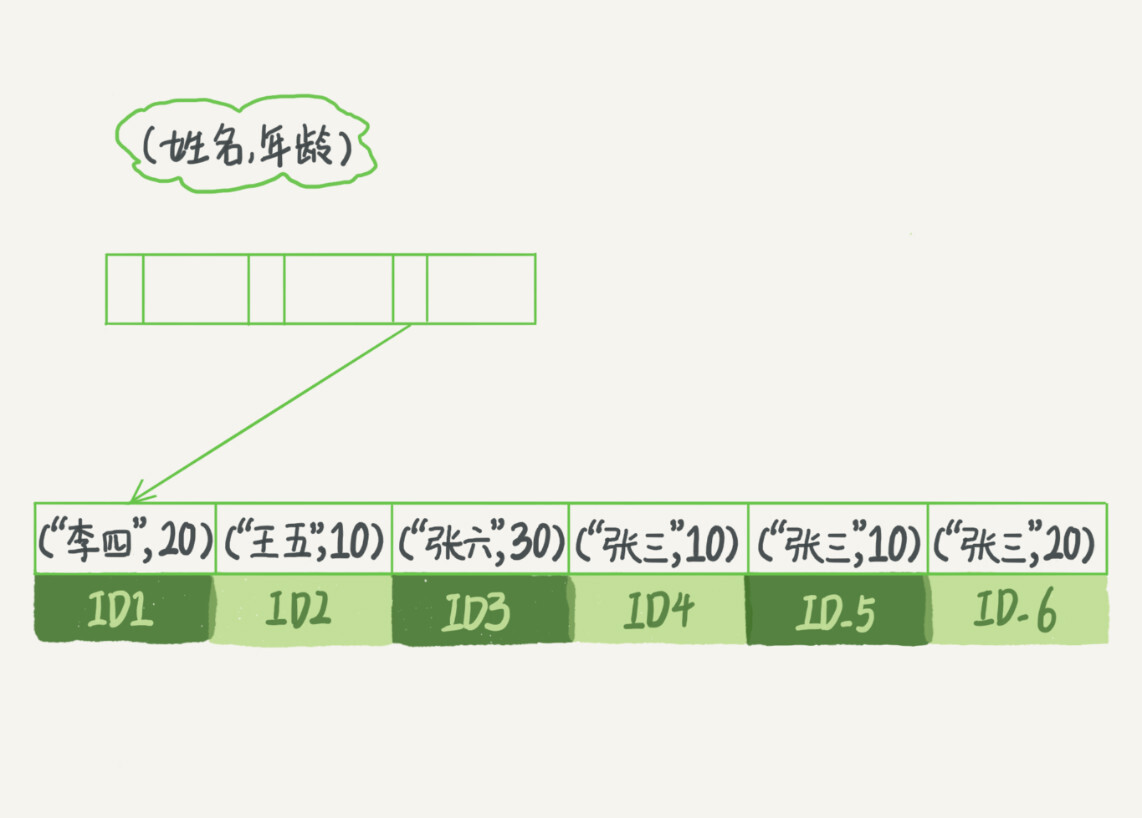
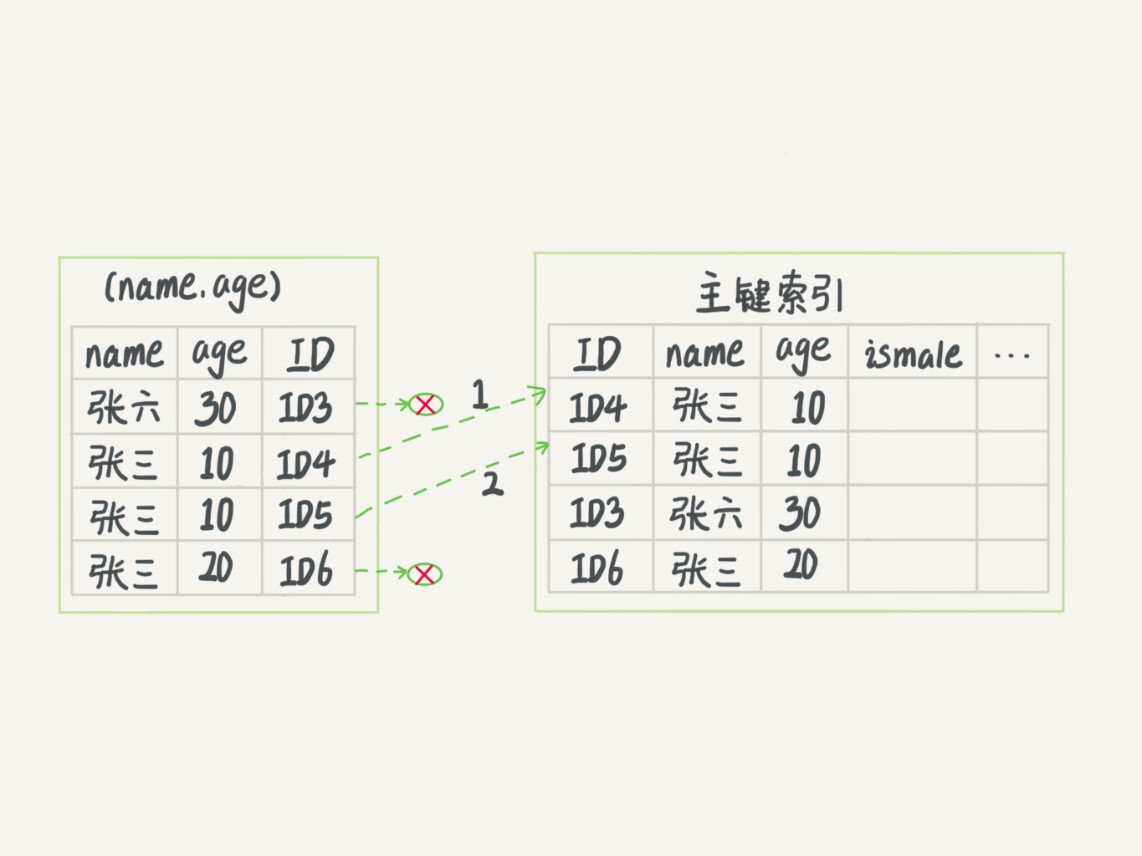
索引下推
可以基于上面(name, age)的索引继续演进,当查询的条件满足两个值时,最左前缀以外的值会下推加入查询判断,如果不满足就不会回表查询,从而提高查询效率。
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
无索引下推执行流程
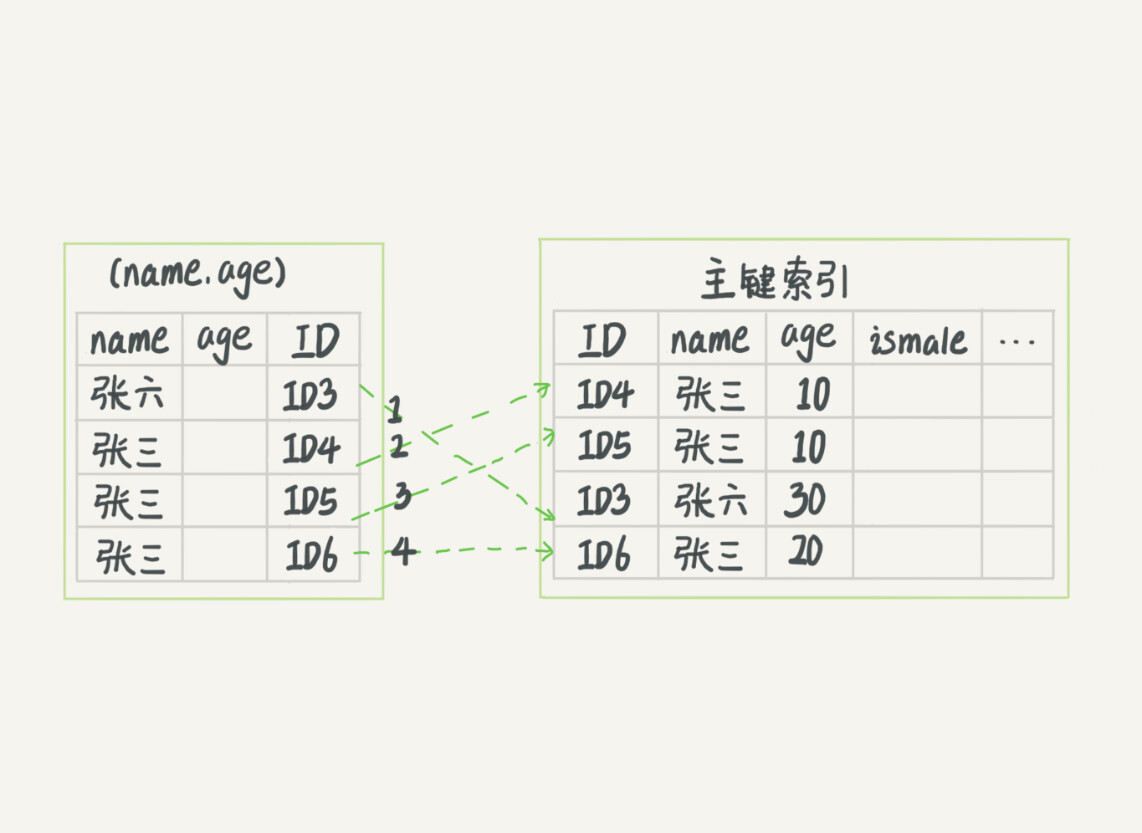
索引下推执行流程
06 | 全局锁和表锁 :给表加个字段怎么有这么多阻碍?
全局锁
- 全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是 Flush tables with read lock (FTWRL)。之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。
- 全局锁的典型使用场景是,做全库逻辑备份。
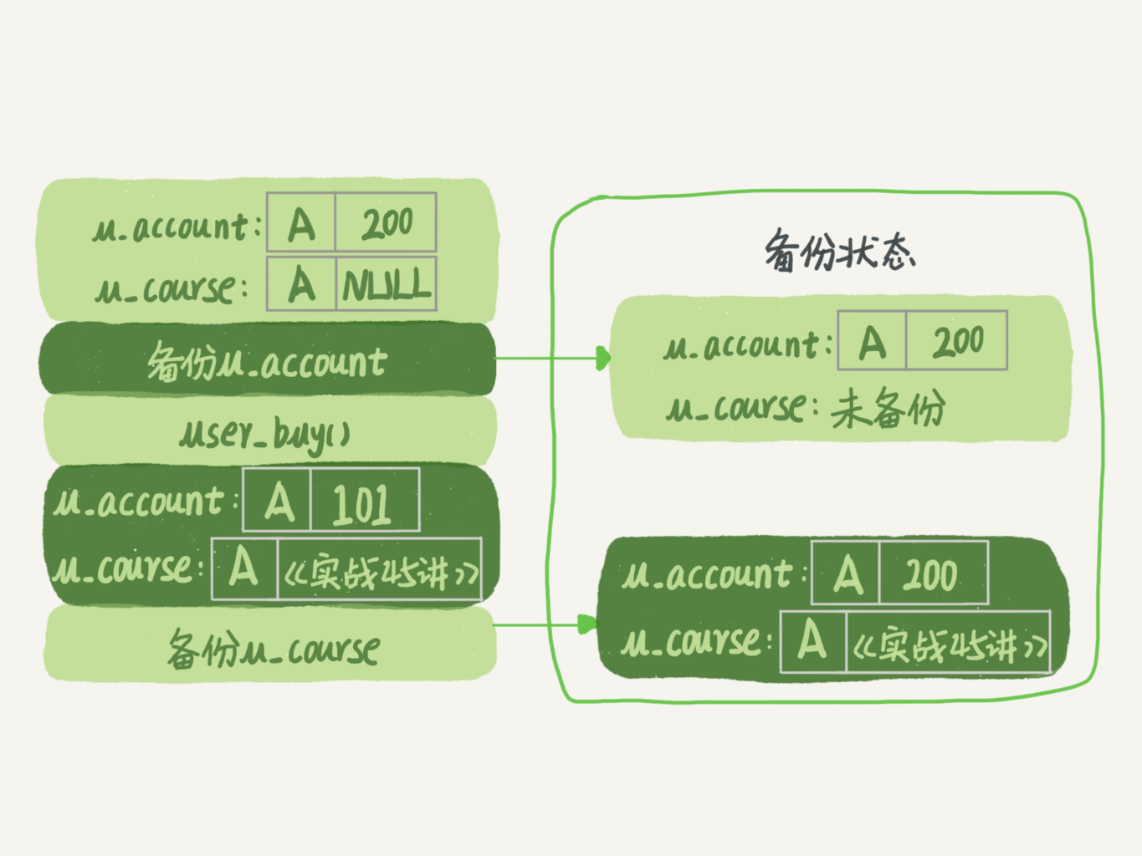
以下买课程,扣钱情景就是典型需要,像“可重复写”的事务隔离级别类似。
表级锁
- 表锁: 语法是 lock tables … read/write。
- 元数据锁 MDL(metadata lock): 简单的说就是DML和DDL的互斥锁。也就是增删改查语句和修改数据库结构语句的互斥锁。在执行CRUD的时候就不- 能改表结构。一般系统是默认加上了的。
07 | 行锁功过:怎么减少行锁对性能的影响?
行锁
行锁: 就是针对数据表中行记录的锁。这很好理解,比如事务 A 更新了一行,而这时候事务 B 也要更新同一行,则必须等事务 A 的操作完成后才能进行更新。
行锁是innodb特有的。
死锁
解决策略:
- 死锁等待: innodb_lock_wait_timeout,超过这个时间就释放。但是容易产生误伤,时间长短不好控制。
- 死锁检测: innodb_deadlock_detect为on时就会检测死锁,然后回滚事务,在mysql中。但是会增加性能消耗。